



Azure Storage Accounts: The Untold Backbone of Cloud Resilience
Inside Azure’s storage engine: Dynamic load balancing, petabyte-scale clusters, and replication secrets revealed. Part 1

Azure Storage Accounts serve as the foundational building blocks for Microsoft’s cloud storage offerings, providing scalable, secure, and highly available storage solutions for various data types. This article delves into the intricate technical architecture of Azure Storage Accounts, exploring how they are structured and how they achieve a high Service Level Agreement (SLA). We will also examine how Azure Managed Disks operate as an abstraction layer on top of these storage accounts, simplifying disk management for virtual machines (VMs).
The Architecture of Azure Storage Accounts
1. Storage Account Structure
At its core, an Azure Storage Account is a container that groups together multiple storage services:
• Blob Storage: For storing unstructured data like images, videos, and documents.
• File Storage: Provides managed file shares accessible via SMB protocol.
• Queue Storage: For message queuing and communication between application components.
• Table Storage: A NoSQL store for structured data. These services are accessible via unique endpoints, and the storage account serves as the namespace and security boundary.
These services are accessible via unique endpoints, and the storage account serves as the namespace and security boundary.
2. Storage Stamp and Cluster Design
Azure’s storage infrastructure is built upon a concept known as a storage stamp.
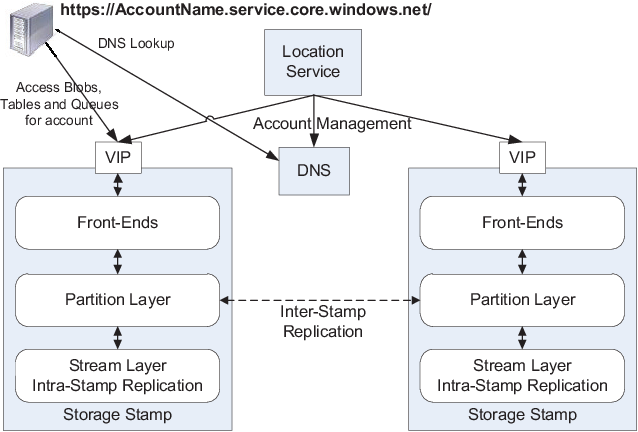
A storage stamp is a cluster of racks, each containing multiple storage nodes, and is designed to scale out horizontally. A storage stamp is usually a cluster of N racks of storage nodes, where each rack is built out as a separate fault domain with redundant networking and power to ensure it’s properly separated in case of issues. Typecally clusters range from 10-20 racks with 18 disk-heavy storage nodes per rack. Their first generation of storage stamps would hold around 2PB of raw storage each, but the latest ones hold up to 30 PB of raw storage each. To ensure a low cost on storage they keep the storage provisioned in production to be as utilized as possible, from documents read a storage stamp is utilized around 70% in terms of capacity/transation/bandwith, avoiding to go above 80% as keeping a a margin like that would ensure continuity in case of a rack failure within a stamp. When the storage stamp reacher ±70% utilization, the location service migrates accounts to other stamps using both asynchronus and synchronus replication.
Location Service
The location service manages all the storage stamps. It’s also responsible for managing the account name space across all stamps. The location services allocates accounts to storage stamps and manages them across the storage stamps for disaster recovery and load balancing. The location service itself is distributed across two geographic locations for it’s own disaster recovery. The LS then chooses a storage stamp within that location as the primary stamp for the account using heuristics based on the load information across all stamps (which considers the fullness of the stamps and other metrics such as network and transaction utilization). The LS then stores the account metadata information in the chosen storage stamp, which tells the stamp to start taking traffic for the assigned account. The LS then updates DNS to allow requests to now route from the name https://AccountName.service.core.windows.net/ to that storage stamp’s virtual IP (VIP, an IP address the storage stamp exposes for external traffic).
Stream Layer
The Stream Layer is responsible for storing bits on disk and managing data distribution and replication across multiple servers to ensure data durability within a storage stamp. Functioning as a distributed file system layer within a stamp, it handles files known as "streams." These streams are ordered lists of large storage chunks called "extents." While the Stream Layer knows how to store and replicate these streams, it does not comprehend higher-level object constructs or their semantics. Although data is stored in the Stream Layer, it is accessed through the Partition Layer. Importantly, partition servers (from the Partition Layer) and stream servers are co-located on each storage node within a stamp.
Partition Layer
The Partition Layer is designed to:
Manage and interpret higher-level data abstractions such as Blobs, Tables, and Queues.
Provide a scalable object namespace to organize and access data efficiently.
Ensure transaction ordering and strong consistency for all objects.
Store object data on top of the Stream Layer, leveraging its storage capabilities.
Cache object data to reduce disk input/output operations and improve performance.
Another critical responsibility of this layer is to achieve scalability by partitioning all data objects within a stamp. Each object is assigned a PartitionName, and objects are divided into disjoint ranges based on these PartitionName values. These ranges are then served by different partition servers. The Partition Layer manages which partition server handles which PartitionName ranges for Blobs, Tables, and Queues. It also provides automatic load balancing of PartitionNames across partition servers to meet the varying traffic demands of the objects.
Front-End (FE) Layer
The Front-End (FE) Layer consists of a set of stateless servers that serve as the entry point for incoming requests. Upon receiving a request, an FE server performs the following steps:
Account Lookup: It retrieves the
AccountNameassociated with the request.Authentication and Authorization: It verifies the credentials and permissions to ensure the requester has the right to access the resource.
Request Routing: Based on the
PartitionName, it routes the request to the appropriate partition server within the Partition Layer.
The system maintains a Partition Map that keeps track of PartitionName ranges and which partition server is responsible for each range. FE servers cache this Partition Map to efficiently determine where to forward each request.
Additional functionalities of the FE servers include:
Direct Streaming of Large Objects: They stream large objects directly from the Stream Layer to optimize data transfer.
Caching Frequently Accessed Data: To enhance efficiency and reduce latency, they cache data that is frequently requested.
By handling these tasks, the Front-End Layer ensures efficient request processing, authentication, and effective routing to the appropriate partition servers.
Replication
Intra-Stamp Replication (Stream Layer)
Intra-Stamp Replication is a system within the Stream Layer that provides synchronous replication to ensure data durability within a storage stamp. Its primary responsibilities include:
Synchronous Replication: It replicates all data written into a stamp in real-time across multiple nodes.
Data Durability: By maintaining enough replicas of the data across different nodes and fault domains, it ensures data remains durable even in the event of disk, node, or rack failures within the stamp.
Fault Tolerance: It distributes replicas across different fault domains to protect against various types of hardware failures.
Critical Path for Write Requests: Intra-stamp replication is on the critical path of customer write requests, meaning that write operations are not considered complete until replication is successfully achieved.
Immediate Success Response: Once a transaction has been successfully replicated within the stamp, the system returns a success response to the customer.
This replication process is entirely managed by the Stream Layer and is crucial for maintaining data integrity and availability within the storage stamp.
Inter-Stamp Replication (Partition Layer)
Inter-Stamp Replication provides asynchronous replication focused on replicating data across different storage stamps. This system operates in the background and is off the critical path of customer requests, ensuring that it does not impact the performance of real-time operations.
Key Features:
Object-Level Replication:
Replicates data at the object level, either by copying the entire object or by replicating recent delta changes for a given account.
Primary Uses:
Disaster Recovery: Maintains a copy of an account's data in two separate locations to protect against data loss due to disasters.
Data Migration: Facilitates the migration of an account's data between stamps for load balancing or maintenance purposes.
Configuration and Execution:
Configured for an account by the Location Service.
Performed by the Partition Layer.
Focus Compared to Intra-Stamp Replication:
Inter-Stamp Replication:
Concentrates on replicating objects and the transactions applied to them.
Ensures data consistency and availability across multiple stamps.
Intra-Stamp Replication:
Focuses on replicating blocks of disk storage used to compose the objects.
Provides data durability within a single stamp.
Reasons for Separate Replication Layers:
Different Objectives and Challenges:
Intra-Stamp Replication:
Durability Against Hardware Failures:
Addresses frequent hardware failures (e.g., disk, node, rack failures) in large-scale systems.
Low Latency Requirement:
Operates on the critical path of user requests, necessitating immediate replication to ensure data durability.
Inter-Stamp Replication:
Geo-Redundancy Against Disasters:
Protects against rare geo-disasters by replicating data across geographically dispersed stamps.
Optimal Network Bandwidth Usage:
Prioritizes efficient use of network bandwidth between stamps while maintaining acceptable replication delays.
Namespace Management:
Intra-Stamp Replication (Stream Layer):
Scoped Information:
Limits the amount of maintained information to the size of a single storage stamp.
Performance Optimization:
Enables caching all meta-state for replication in memory, providing fast replication with strong consistency.
Quickly commits transactions within a single stamp for customer requests (see Section 4 for details).
Inter-Stamp Replication (Partition Layer and Location Service):
Global Namespace Control:
Manages and understands the global object namespace across stamps.
Efficient Cross-Data Center Operations:
Efficiently replicates and maintains object state across data centers.
By separating replication into Intra-Stamp and Inter-Stamp at two different layers, the system addresses distinct challenges:
Intra-Stamp Replication ensures rapid, synchronous data replication within a stamp to protect against common hardware failures without adding latency to user requests.
Inter-Stamp Replication provides asynchronous data replication across stamps to safeguard against rare geo-disasters and to facilitate data migration, focusing on network efficiency rather than immediacy.
This layered approach allows each replication system to optimize for its specific goals—whether that's low-latency durability within a stamp or efficient, scalable replication across multiple stamps—ultimately enhancing the overall reliability and performance of the storage system.
Conclusion
Azure Storage Accounts exemplify Microsoft's commitment to providing robust, scalable, and highly available cloud storage solutions. Through a sophisticated multi-layered architecture, Azure ensures seamless data management, durability, and resilience. From the intricate design of storage stamps to the seamless integration of replication strategies and namespace management, Azure has engineered a system that not only meets but often exceeds enterprise-grade requirements.
This documentation is a summarized compilation of insights drawn from various Azure technical resources and official Microsoft documentation. Where possible, passages and technical details have been directly referenced to ensure accuracy and clarity. This approach ensures a comprehensive understanding of the system while giving full credit to the original documentation sources. For deeper insights or specifics, readers are encouraged to refer to Azure’s official storage documentation and the link to the documentation here.